So I had planned on shutting down my ESXi host that lives outside of the cluster, the one that manages my TrueNAS and vCenter. But if vCenter is running on that host, how then does it update it? Answer is, if it’s running on the same host, it can’t. In a HA setup, vCenter would vMotion to another host. But in the case where it’s not in HA, you’d just do so from the command-line.
I won’t go into how to upgrade a ESXi host from the command line. There are plenty of guides out there — William Lam’s Guide (albeit using an old version of ESXi) or this guide are good resources, as are the VMware documentation.
I started asking myself, why do I not have a backup vCenter, just in case something happens. vCenter already has an “HA” feature built in — why not use that? Having backups is one thing, but how long will it take to recover from a backup? Or, the host running vCenter goes down. I don’t want to lose access to vCenter, just because one of my nodes are down.
VMWare defines vCenter HA as:
vCenter High Availability (vCenter HA) protects vCenter Server against host and hardware failures. The active-passive architecture of the solution can also help you reduce downtime significantly when you patch vCenter Server.
After some network configuration, you create a three-node cluster that contains Active, Passive, and Witness nodes. Different configuration paths are available. What you select depends on your existing configuration.
What happens is, vCenter will add another network interface to itself, which is used for the three nodes to communicate with each other. It then will deploy another vCenter instance and copy the configuration from the running vCenter. The Primary NIC is configured, but not enabled. vCenter configures the MAC address of the interface to be the same.
Once the “passive” vCenter is deployed, the “witness” node is deployed. This node ONLY has one NIC, attached to the vCenter HA Network. The witness node then monitors the health of both nodes, and if it detects a issue, will automatically initiate a failover, and the passive will then become to master. You can also trigger a fail-over. If you initiate a failover, you have the option to start the failover now, which may or may not sync any config changes. Or you can select to failover after all config sync tasks are complete. Obviously, if the witness detects the primary host down, it will initiate failover and not wait.
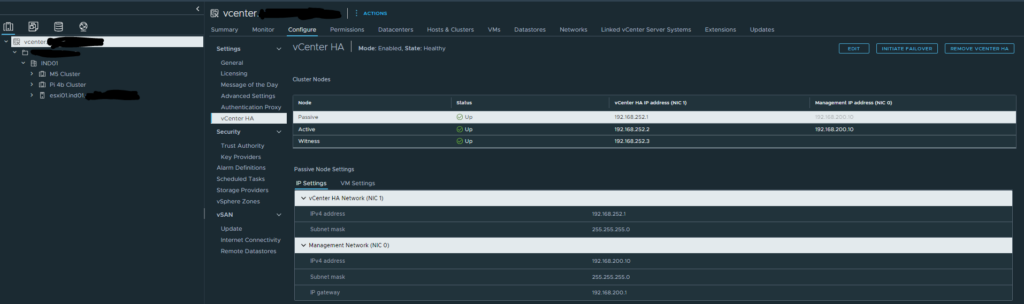
As you can see, I have already manually initiated a failover, and the passive is now the active vCenter. This is denoted by the passive being listed first in the list. Now that we have vCenter actually running on a different host, we can finally upgrade esxi01.
First, I manually shutdown the TrueNAS VM and the vCenter VM (which is now the passive instance). Once both were shutdown, I went to the Updates tab, and via LCM selected the new baseline I wanted, and staged the host.
Staging prepares the host for the next version. It prepares the software so it’s ready to be installed. Once done, remediation time. Remediation is just as it sounds, it’s taking the updates and applying them. LCM will place the host into maintenance mode, then begin the upgrade. Once complete, LCM will power-cycle the host. Hopefully, all is well and the host comes back online in maintenance mode.
Here, you would verify that you have upgrade versions. Once known everything is fine, take the host out of maintenance mode and re-start the VMs. Now you have a choice to make. Do you initiate another failover and move the primary node back to it’s original location? Or just let it stay as it is?
I ultimately left everything like it is. But now I know my vCenter is completely protected (in theory). I can now use LCM to manage the entire cluster and upgrades (including my Raspberry Pi Cluster). Now just to get UCS Manager going, and the integration between vCenter and UCS Manager. Manage the firmware of all my nodes, make sure everything is running compatible and recommended versions, plus enable Predictive DRS which will use the UCS Manager to monitor the physical host’s health, and if it detects an system issue, move VMs off that host.