I am currently running ESXi 8.0u2-22380479. I typically use the Cisco Custom Image to install and update my cluster. But if you know anything about Cisco, they are insanely slow to release their Custom ISOs. For instance, ESXi 8.0 U2b – 23305546 was released on 2/29/2024. and U2c on 05/21/2024. The Cisco UCS Addon v4.3.2-c was not released until 4/3/2024 — Almost 2 months after U2B came out. This is the same with the current version – ESXI 8.0 U3 – 24022510. It’s been available since 6/25/24, but no Cisco Custom Image.
While I normally would just wait, there’s a new feature that I am excited about. vSphere Memory Tiering – Tech Preview in vSphere 8.0U3. This allows you to use some of your NVMe drive space as actual memory! Scaling memory has just gotten insanely cheap — I can buy a few 1TB NVMe drives cheap, and add up to 400% my current memory per host. Talk about crazy. PLUS, since I will not be using 100% of the NVMe drive, the remaining would be available for a local datastore, but since I’m running vSAN — local datastores defeat the purpose of High Availability.
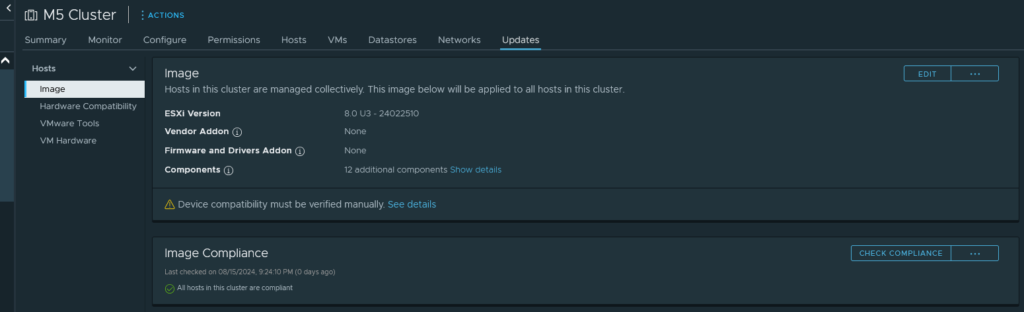
I’m tired of waiting. There’s a feature called vSphere Lifecycle Manager (vLCM) UI within vCenter where you can manage your clusters image, automatically stage and upgrade hosts in a rolling manner, etc. This process also allows you to inject other needed drivers into the image, thus creating your own Custom ISO (You can even export to an bootable ISO).
So, after verifying outside of the custom Cisco VIBs, everything else is compatible (vLCM will tell you what’s compatible, what’s not, if any configurations are not supported, etc), I started my custom image build. William Lam has a great write-up on using vLCM to update, and I used this as a starting point to creating my image. After injecting the needed Cisco drivers, and a couple other drivers for other equipment (there were some updates to other drivers that the Custom Cisco ISO did not have), time to check the cluster.
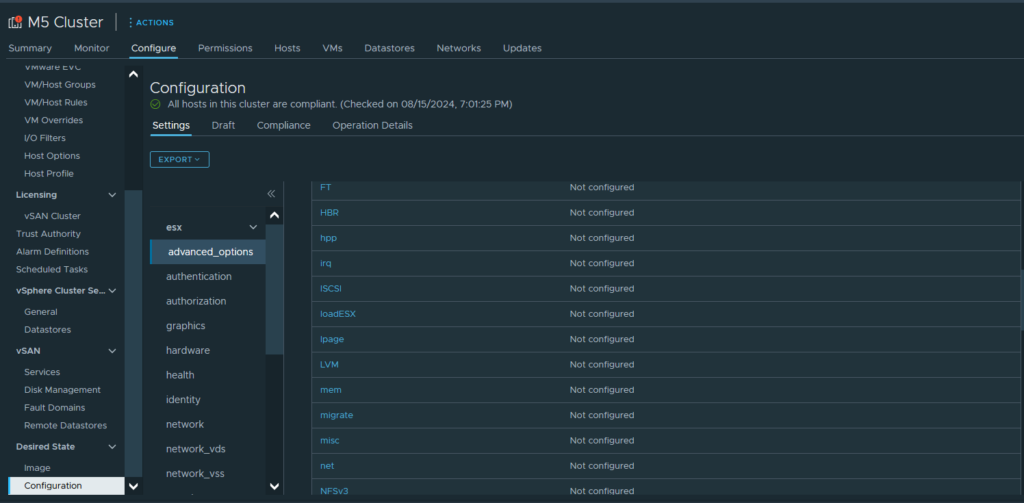
Here, I ran into another issue. There was an advanced configuration option selected that was not supported. To tell you the truth, I don’t remember ever setting this, and the default setting is what I had manually set. So a quick jump to Configure ->Desired State -> Configuration, then locating /esx/advanced_options/mem I removed the setting, and away we go…. maybe.
But alas, somehow the image was not compatible with my hosts. Reviewing the error, it mentioned:
Downgrades of Addon Components Marvell Technology Network/iSCSI/FCoE/RDMA E4
drivers(5.0.305.0-1OEM), Network driver for Intel(R) 1 Gigabit Server Adapters(igbn-1.11.2.0), Network driver for Intel(R) E810 Adapters(icen-1.11.3.0), QLogic NetXtreme II 10 Gigabit Ethernet FCoE and iSCSI Drivers(3.0.182.0-1OEM) in the desired ESXi version are not supported.Apparently, I must have unselected these drivers and vCenter considers removing a downgrade, and this wasn’t possible. Like I said, vCenter will tell you if there’s an issue with your config BEFORE deploying it to your cluster. After I went back and re-added these drivers (and updated the versions), success.
The beautiful part of all this — Outside of two VMs that rely on GPU passthrough, the entire process is automated. And soon, i’ll have my vGPU cluster setup — once that happens, any VM can move to ANY host and still have access to its vGPU.
I still have one host to go — the host that’s outside of the cluster (esxi01). This host runs my TrueNAS VM, vCenter, etc. I will have to schedule a maintenance window (yeah, i know — homelab. But I run production workloads, so …). This is the host that’s really going to benefit from the new Memory Tiering. Since this machine is limited to one CPU, and supports only 8 memory bays — memory is a premium here. While true, I could buy some 64 gig DDR4 Memory, the price is more than I care to spend. I have a 512GB NVMe drive sitting around doing nothing — I should be able to bump that machine to 640GB ram.
What do I need so much memory on this host for? Well — One of the great things about virtualization is, you can oversubscribe your resources. That’s not the case when you have hardware PCI passthrough enabled on a VM. The memory is LOCKED to that VM, and not available for any other VMs. While I try not to overprovision memory, with vCenter and TrueNAS — this host is pretty maxed out.
ZFS loves memory. The more I can throw at it, the better it performs. Now with NVMe tiering, I can dedicated 128GB or 256GB ram to TrueNAS, and still have approximately 469GB for other VMs (that’s also including the memory for vCenter, and the host OS).
There are a few things I want to run outside of my cluster. Aria Operations, Aria Logs, Monitoring, etc. Before, while I could, memory would be an issue. Now, this gets rid of that limitation and I can safely deploy other services here.
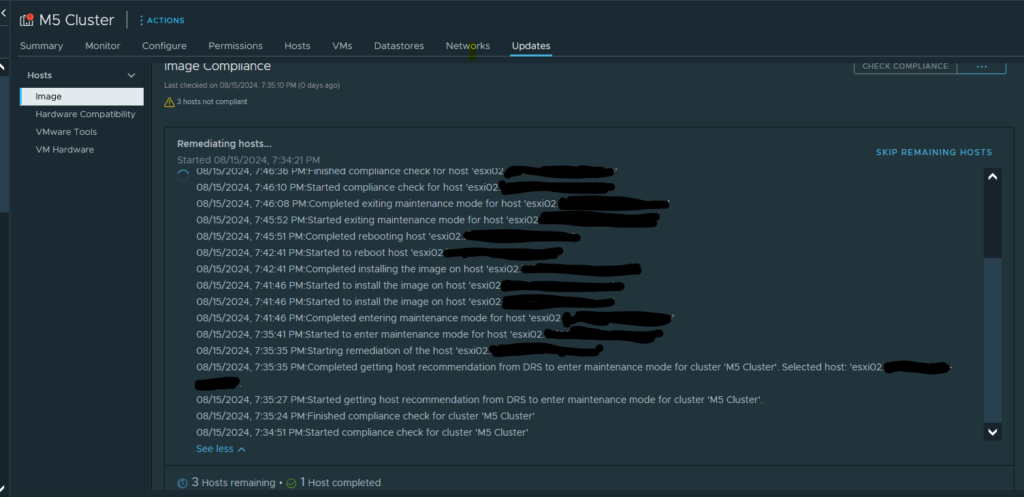
I got too cocky. I thought things were going fine. 2 hosts have updated, and the 3rd had started. But this one was taking a lot longer to evacuate data to the other nodes. A little investigating, and for some reason, the drives on esxi02 were not detected. ESXi saw the drives, but was registering them as 0GB, and offline. I checked via CIMC and the drives appeared there fine, and no errors. Once I removed and reinserted the drives, and forced the storage to rescan, all drives were detected and automatically reclaimed by vSAN. So now, instead of walking away and letting vLCM do it’s thing, I am going to sit here and make sure all nodes recover properly.
Tomorrow, I will tackle upgrading my vCenter. For some reason, I have more problems upgrading vCenter than a person should. I had previously updated vCenter to the U3 update, but had to revert. vCenter itself was working fine. But the VAMI – Virtual Appliance Management Interface would not work. Whenever I would browse to it, I would be dropped back into the configure portion, where you have the option of Upgrading vCenter, Migrating, etc. None of these options are what I want. The appliance had been successfully updated. But something was locked, and I could not find what. I tried multiple suggestions, multiple KBs, even my battles with vCenter but nothing worked. This would not be a problem, if this did not completely stop vCenter backups from happening. I’ve learned my lessons about not having a tested, working backup. Snapshots are fine, but they are not a backup, and should not be used as one. I will, however take a snapshot before I begin. If I run into the same issue, I will immediately revert, and try something else.

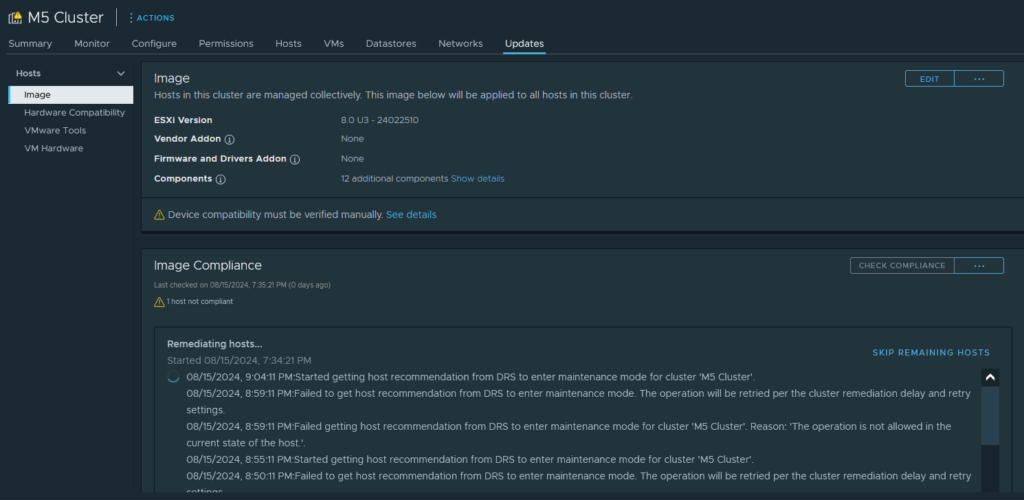
SUCCESS
My Cisco UCS M5 Cluster has been successfully upgraded. Maintenance window has been setup for Saturday, 8/17/2024 @ 2AM EST to upgrade the final host. What’s next? Kubernetics is still the plain. But there are a few things I need to take care of first. I discovered my iSCSI shares do not automatically reconnect if the NAS is down when the hosts first boot. There’s an easy fix, involves running a script on the NAS to force ESXi to rescan all HBAs. I need to recover my gitlab instance, and upgrade all my Ubuntu hosts. Since my Ansible Tower instance relies on GitLab, I have to get that taken care of first.